Cliff L. Biffle blogged a great write-up of a debugging odyssey at Oxide with the title Who killed the network switch? Here’s the bit that jumped out at me:
At the time that code was written, it was correct, but it embodied the assumption that any loaned memory would fit into one region.
That assumption became obsolete the moment that Matt implemented task packing, but we didn’t notice. This code, which was still simple and easy to read, was now also wrong.
This type of assumption is an example of an invariant, a property of the system that is supposed to be guaranteed to not change over time. Invariants play an important role in formal methods (for example, see the section Writing an invariant in Hillel Wayne’s Learn TLA+ site).
Now, consider the following:
Our systems change over time. In particular, we will always make modifications to support new functionality that we could not have foreseen earlier in the lifecycle of the system.
Our code often rests on a number of invariants, properties that are currently true of our system and that we assume will always be true.
These invariants are implicit: the assumptions themselves are not explicitly represented in the source code. That means there’s no easy way to, say, mechanically extract them via static analysis.
A change can happen that violates an assumed invariant can be arbitrary far away from code that depends on the invariant to function properly.
What this means is that these kinds of failure modes are inevitable. If you’ve been in this business long enough, you’ve almost certainly run into an incident where one of the contributors was an implicit invariant that was violated by a new change. If you’re system lives long enough, it’s going to change. And one of those changes is eventually going to invalidate an assumption that somebody made long ago, which was a reasonable assumption to make at the time.
Implicit invariants are, by definition, impossible to enforce explicitly. They are time bombs. And they are everywhere.
The Toyota-themed book I’m currently reading is Mike Rother’s Toyota Kata: Managing People for Improvement, Adaptiveness and Superior Results. Rother often uses the phrase “go and see”, as in “go to the shop floor and observe how the work is actually being done”. I’ve often heard lean advocates use a similar phrase: go the gemba, although Rother himself doesn’t use it in his book. There’s a good overview at the Lean Enterprise Institute’s web page for gemba:
Gemba (現場) is the Japanese term for “actual place,” often used for the shop floor or any place where value-creating work actually occurs. It is also spelled genba. Lean Thinkers use it to mean the place where value is created. Japanese companies often supplement gemba with the related term “genchi gembutsu” — essentially “go and see” — to stress the importance of empiricism.
The idea of focusing on understanding work-as-done is a good one. Unfortunately, in software development in particular, and knowledge work in general, the place that the work gets done is distributed: it happens wherever the employees are sitting in front of their computers. There’s no single place, no shop floor, no gemba that you can go to in order to go and see the work being done.
Now, you can observe the effects of the work, whether it’s artifacts generated (pull requests, docs), or communication (slack messages, emails). And you can talk to people about the work that they do. But, it’s not like going to the shop floor. There is no shop floor.
And it’s precisely because we can’t go to the gemba that incident analysis can bring so much value, because it allows you to essentially conduct a miniature research project to try to achieve the same goal. You get granted some time (a scarce resource!) to reconstruct what happened, by talking to people and looking at those work products generated over time. If we’re good at this, and we’re lucky, we can get a window into how the real work happens.
In the wake of an incident, we want to answer the questions “What happened?” and, afterwards, “What should we do differently going forward?” Invariably, this leads to people trying to answer the question “what went wrong?”, or, even more specifically, the two questions:
What did we do wrong here?
What didn’t we do that we should have?
There’s an implicit assumption behind these questions that because there was a bad outcome, that there must have been a bad action (or an absence of a good action) that led to that outcome. It’s such a natural conclusion to reach that I’ve only ever seen it questioned by people who have been exposed to concepts from resilience engineering.
In some sense, this belief in bad outcomes from bad actions is like Aristole’s claim that heavier objects fall faster than lighter ones. Intuitively, it seems obvious, but our intuitions lead us astray. But in another sense, it’s quite different, because it’s not something we can test by running an experiment. Instead, the idea that systems fail because somebody did something wrong (or didn’t do something right) is more like a lens or a frame, it’s a perspective, a way of making sense of the incident. It’s like how the fields of economics, psychology, and sociology act as different lenses for making sense of the world: a sociological explanation of a phenomenon (say, the First World War) will be different from an economic explanation, and we will get different insights from the different lenses.
An alternative lens for making sense of an incident is to ask the question “how did this incident happen, assuming that everybody did everything right?” In other words, assume that everybody whose actions contributed to the incident made the best possible decision based on the information they had, and the constraints and incentives that were imposed upon them.
Looking at the incident from this perspective will yield will very different kinds of insights, because it will generate different types of questions, such as:
What information did people know in the moment?
What were the constraints that people were operating under?
Now, I personally believe that the second perspective is strictly superior to the first, but I acknowledge that this is a judgment based on personal experience. However, even if you think the first perspective also has merit, if you truly want to maximize the amount of insight you get from a post-incident analysis, then I encourage you to try to the second perspective as well. Make the claim “Let’s assume everybody did everything right. How could this incident still have happened?” I guarantee, you’ll learn something new about your system that you didn’t know before.
There are two general approaches to decision-making. One way is to make a judgment call. Informally, you could call this “trusting your gut”. Formally, you could describe this as a subjective, implicit process. The other way is to use an explicit approach that relies on objective, quantitative data, for example, doing a return-on-investment (ROI) calculation on a proposed project to decide whether to undertake the project. We use the term rigorous to describe these type of approaches, and we generally regard them as superior.
Here, Porter argues that quantitative, rigorous decision-making in a field is not a sign of its maturity, but rather its political weakness. In fields where technical professionals enjoy a significant amount of trust, these professionals do decision-making using personal judgment. While professionals will use quantitative data as input, their decisions are ultimately based on their own subjective impressions. (For example, see Julie Gainsburg’s notion of skeptical reverence in The Mathematical Disposition of Structural Engineers). In Porter’s account, we witnessed an increase of rigorous decision-making approaches in the twentieth century because of a lack of trust in certain professional fields, not because the quantitative approaches yielded better results.
It’s only in fields where the public does not grant deference to professionals that they are compelled to use explicit, objective processes to make the decisions. They are forced to show their work in a public way because they aren’t trusted. In some cases, a weak field adopts rigor to strengthen itself in the eyes of the public, such as experimental psychology’s adoption of experimental rigor (in particular, ESP research). Most of the case studies in the book come from areas where a field was compelled to adopt objective approaches because there was explicit political pressure and the field did not have sufficient power to resist.
In some cases, professionals did have the political clout to push back. An early chapter of the book discusses a problem that the British parliament wrestled with in the late nineteenth century: unreliable insurance companies that would happily collect premiums but then would eventually fail and would hence be unable to pay out when their customers submitted claims. A parliamentary committee formed and heard testimony from actuaries about how the government could determine whether an insurance company was sound. The experienced actuaries from reputable companies argued that it was not possible to define an objective procedure for assessing the a company. They insisted that “precision is not attainable through actuarial methods. A sound company depends on judgment and discretion.” They were concerned that a mechanical, rule-based approach wouldn’t work:
Uniform rules of calculation, imposed by the state, might yield “uniform errors.” Charles Ansell, testifying before another select committee a decade earlier, argued similarly, then expressed his fear that the office of government actuary would fall to “some gentlemen of high mathematical talents, recently removed from one of our Universities, but without any experience whatever, though of great mathematical reputation.” This “would not qualify him in any way whatever for expressing a sound opinion on a practical point like that of the premiums in a life assurance.”
Trust in Numbers, pp108-109
Porter tells a similar story about American accountants. To stave off having standardized rules imposed on them, the American Institute of Accountants defined standards for its members, but these were controversial. One accountant, Walter Wilcox, argued in 1941 that “Cost is not a simple fact, but is a very elusive concept… Like other aspects of accounting, costs give a false impression of accuracy.” Similarly, when it came to government-funded projects, the political pressure was simply too strong to defer to government civil engineers, such as the French civil engineers who had to help decide which rail projects should be funded, or the U.S. Army Corps of Engineers who had to help make similar decisions about waterway projects such as dams and reservoirs. In the U.S., they settled on a cost-benefit analysis process, where the return on investment had to exceed 1.0 in order to justify a project. But, unsurprisingly, there were conflicts over how benefits were quantified, as well as over how to classify costs. While the output may have been a number, and the process was ostensibly objective, because it needed to be, ultimately these numbers were negotiable and assessments changed as a function of political factors.
In education, teachers were opposed to standardized testing, but did not have the power to overcome it. On the other hands, doctors were able to retain the use of their personal judgment for diagnosing patients. However, the regulators had sufficient power that they were able to enforce the use of objective measures for evaluating drugs, and hence were able to oversee some aspect of medical practice.
This tug of war between rigorous, mechanical objectivity and élite professional autonomy continues to this day. Professionals say “This requires private knowledge; trust us”. Sometimes, the public says “We don’t trust you anymore. Make the knowledge public!”, and the professionals have no choice but to relent. On the subject of whether we are actually better off when we trade away judgment for rigor, Porter is skeptical. I agree.
I’ve just started reading Trust in Numbers: The Pursuit of Objectivity in Science and Public Life by the historian of science Theodore Porter, and so far it’s fantastic. The first chapter discusses how, in the days before the metric system, even units of measure were negotiable. Porter gives two examples. One example comes from Poland, where the size of a unit of land would sometimes vary based on the quality of the soil, to make adjustments to equalize the amount of productive land, rather than simply the area of the land.
The other example Porter gives is about the reference vessel that towns would use to as their local definition of a bushel. You might think that defining a specific vessel as the bushel would give a fixed definition, but there was still flexibility. The amount of say, grain, or oat, that could be poured into the vessel could vary, depending on how it was poured (e.g., whether the material was “flattened” or “heaped”, the height it was poured from). This allowed people to make adjustments on the actual volume that constituted a bushel based on factors such as quality.
We humans have to build systems in order to scale up certain kinds of work: we couldn’t have large-scale organizations like governments and corporations without the technologies of bureaucracies and other forms of standardization. This is the sort of thing that James Scott calls legibility. But these formal systems demand fixed rules, which can never fully accommodate the messiness that comes with operating in the real world. And so, the people at the sharp end, the folks on the ground who are doing the actual work of making the system go, have to deal with this messiness that the system’s designers did not account for.
For these people to be able to do their work, there needs to be some give in the system. The people need to be able to exercise judgment, some ability to negotiate the boundaries of the rules of the system. Every human system is like this: the actors must have some amount of flexibility, otherwise the rules of the system will prevent people from being able to achieve the goals of the system. In other words, negotiability in a system is non-negotiable.
Reporting an outcome’s occurrence consistently increases its perceived likelihood and alters the judged relevance of data describing the situation preceding the event.
In my last blog post, I wrote about how computer scientists use execution histories to reason about consistency properties of distributed data structures. One class of consistency properties is known as causal consistency. In my post, I used an example that shows a violation of causal consistency, a property called writes follows reads.
Here’s the example I used, with timestamps added (note: this is a single-process example, there’s no multi-process concurrency here).
Now, imagine this conversation between two engineers who are discussing this queue execution history.
A: “There’s something wrong with the queue behavior.”
B: “What do you mean?”
A: “Well, the queue was clearly empty at t=0, and then it had a value at t=1, even though there was no write.”
B: “Yes, there was, at t=2. That write is the reason why the queue read [“A: Hello”] at t=1.”
We would not accept that answer given by B, that the read seen at t=1 was due to the write that happened at t=2. The reason we would reject it is that this violates are notion of causality: the current output of a system cannot depend on its future inputs!
It’s not that we are opposed to the idea of causal systems in principle. We’d love to be able to build systems that can see into the future! It’s that such systems are not physically realizable, even though we can build mathematical models of their behavior. If you build a system whose execution histories violate causal consistency, you will be admonished by distributed systems engineers: something has gone wrong somewhere, because that behavior should not be possible. (In practice, what’s happened is that events have gotten reordered, rather than an engineer having accidentally built a system that can see into the future).
In the wake of an incident, we often experience the exact opposite problem: being admonished for failing to be part of a non-causal system. What happens is that someone will make an observation that the failure mode was actually foreseeable, and that engineers erred by not being able to anticipate it. Invariably, the phrase “should have known” will be used to describe this lack of foresight.
The problem is, this type of observation is only possible with knowledge of how things actually turned out. They believe that the outcome was foreseeable because they know that it happened. When you hear someone say “they should have known that…”, what that person is in fact saying is “the system’s behavior in the past failed to take into account future events”.
This sort of observation, while absurd, is seductive. And it happens often enough that researchers have a name for it: hindsight bias, or alternately, creeping determinism. The paper by the engineering researcher Baruch Fischhoff quoted at the top of this post documents a controlled experiment that demonstrates the phenomenon. However, you don’t need to look at the research literature to see this effect. Sadly, it’s all around us.
So, whenever you hear “X should have”, that should raise a red flag, because it’s an implicit claim that it’s possible to build non-causal systems. The distributed systems folks are right to insist on causal consistency. To berate someone for not building an impossible system is pure folly.
“Thanks! I’m excited to be here. This is my first tech job, even if it is just an internship.”
“We’re going to start you off with some automated testing. You’re familiar with queues, right?”
“The data structure? Sure thing. First in, first out.”
“Great! We need some help validating that our queueing module is always working properly. We have a bunch of test scenarios written, and we want need to someone to check that the observed behavior of the queue is correct.”
“So, for input, do I get something like a history of interactions with the queue? Like this?”
q.add("A") -> OK q.add("B") -> OK q.pop() -> "A" q.add("C") -> OK q.pop() -> "B" q.pop() -> "C"
“Exactly! That’s a nice example of a correct history for a queue. Can you write a program that takes a history like that as input and returns true if it’s a valid history?”
“Sure thing.”
“Excellent. We’ll also need your help generating new test scenarios.”
A few days later
“I think I found a scenario where the queue is behaving incorrectly when it’s called by a multithreaded application. I got a behavior that looks like this:”
q.add("A") -> OK q.add("B") -> OK q.add("C") -> OK q.pop() -> "A" q.pop() -> "C" q.pop() -> "B"
“Hmmm. That’s definitely incorrect behavior. Can you show me the code you used to generate the behavior?”
“Sure thing. I add the elements to the queue in one thread, and then I spawn a bunch of new threads and dequeue in the new threads. I’m using the Python bindings to call the queue. My program looks like this.”
from bigco import Queue from threading import Thread
“Well, that’s certainly not the order I expect the output to be printed in, but how do you know the problem is that the queue is actually behaving correctly? It might be that the values were dequeued in the correct order, but because of the way the threads are scheduled, the print statements were simply executed in a different order than you expect.”
“Hmmm. I guess you’re right: just looking at the order of the printed output doesn’t give me enough information to tell if the queue is behaving correctly or not. Let me try printing out the thread ids and the timestamps.”
[id0] [t=1] before pop [id0] [t=2] after pop [id0] [t=3] output: A [id1] [t=4] before pop [id2] [t=5] before pop [id2] [t=6] after pop [id2] [t=7] output: C [id1] [t=8] after pop [id1] [t=9] output: B
“Oh, I see what happened! The operations of thread 1 and thread 2 were interleaved! I didn’t think about what might happen in that case. It must have been something like this:”
“Well, it looks like the behavior is still correct, the items got dequeued in the expected order, it’s just that they got printed out in a different order.”
The next day
“After thinking through some more multithreaded scenarios, I ran into a weird situation that I didn’t expect. It’s possible that the “pop” operations overlap in time across the two different threads. For example, “pop” might start on thread 1, and then in the middle of the pop operation, the operating system schedules thread 2, and it starts in the middle.”
[id0] [id1] [id2] q.pop(): start q.pop(): end print("A") q.pop(): start | q.pop(): start q.pop(): end | q.pop(): end print("C") print("B")
“Let’s think about this. If id1 and id2 overlap in time like this, what do you think the correct output should be? ‘ABC’ or ‘ACB’?”
“I have no idea. I guess we can’t say anything!”
“So, if the output was ‘ABB’, you’d consider that valid?”
“Wait, no… It can’t be anything. It seems like either ‘ABC’ or ‘ACB’ should be valid, but not “ABB”.
“How about ‘BCA’? Would that be valid here?”
“No, I don’t think so. There’s no overlap between the first pop operation and the others, so it feels like the pop in id0 should return “A”.
“Right, that makes sense. So, in a concurrent world, we have potentially overlapping operations, and that program you wrote that checks queue behaviors doesn’t have any notion of overlap in it. So we need to be able to translate these potentially overlapping histories into the kind of sequential history your program can handle. Based on this conversation, we can use two rules:
1. If two operations don’t overlap (like the pop in id0 and the pop in id1) in time, then we use the time ordering (id0 happened before id1).
2. If two operations do overlap in time, then either ordering is valid.
“So, that means that when I check whether a multithreaded behavior is valid, I need to actually know the time overlap of the operations, and then generate multiple possible sequential behaviors, and check to see if the behavior that I witnesses corresponds to one of those?”
“Yes, exactly. This is a consistency model called linearizability. If our queue has linearizable consistency, that means that for any behavior you witness, you can define a linearization, an equivalent sequential behavior. Here’s an example.”
“The question is: can we generate a linearization based on the two rules above? We can! Because the “id1” and “id2” overlap, we can generate a linearization where the “id1″ operation happens first. One way to think about it is to identify a point in time between the start and end of the operation and pretend that’s when the operation really happens. I’ll mark these points in time with an ‘x’ in the diagram.
“We’re expanding our market. We’re building on our queue technology to build a distributed queue. We’re also providing a new operation: “get”. When you call “get” on a distributed queue, you get the entire contents of the queue, in queue order.”
“Oh, so a valid history would be something like this?”
“Exactly! One use case we’re targeting is using our queue for implementing online chat, so the contents of a queue might look like this:”
["Alice: How are you doing?", "Bob: I'm fine, Alice. How are you?", "Alice: I'm doing well, thank you."]
CAPd
“OK, I did some testing with the distributed queue. ran into a problem with the distributed queue. Look at this history, it’s definitely wrong. Note that the ids here are process ids, not thread ids, because we’re running on different machines.
“When process 1 called ‘get’, it didn’t see the “Alice: Hello” entry, and that operation completed before the ‘get’ started! This history isn’t linearizable!”
“You’re right, our distributed queue isn’t linearizable. Note that we could modify this history to make it linearizable if process 0’s add operation did not complete until after the get:
[id0] [id1] q.add("Alice: Hello"): start
q.add("Bob: "Hi"): start q.add(...) -> OK q.get(): start q.get()-> ["Bob: Hi"] q.add(...) -> OK
“Now we can produce a valid linearization from the history”
“But look what we had to do: we had to delay the completion of that add operation. This is the lesson of the CAP theorem: if you want your distributed object to have linearizable consistency, then some operations might take an arbitrarily long time to complete. With our queue, we decided to prefer availability, so that all operations are guaranteed to complete within a certain period of time. Unfortunately, once we give up on linearizability, things can get pretty weird. Let’s see how many different types of weird things you can find.”
Monotonic reads
“Here’s a weird one. The ‘Hi’ message disappeared in the second read!”
“Yep, this violates a property called monotonic reads. Once process 0 has seen the effect of the add(“B: Hi”) operation, we expect that it will always see it in the future. This is an example of a session property. If the two gets happened on two different processes, this would not violate the monotonic reads property. For example, the following history doesn’t violate monotonic reads, even though the operations and ordering are the same. That’s because one of the gets is in process 0, and the other is in process 1, and the monotonic reads property only applies to reads within the same process.
“All right, let’s say we can guarantee monotonic reads. What other kinds of weirdness happen?”
Read your writes
[id0] q.add("A: Hello") q.get() -> []
“Read your writes is one of the more intuitive consistency properties. If a process writes data, and then does a read, it should be able to see the effective of the write. Here we did a write, but we didn’t see it.”
“Here’s a case where read-your-writes isn’t violated (in fact, we don’t do any reads after the write), but something very strange has happened. We saw the effect of our write before we actually did the write! This violates the writes follow reads property. This also called session causality, and you can see why: when it was violated, we saw the effect before the cause!”
Monotonic writes
[id0] [id1] q.add("A: Hi there!") q.add("A: How are you?") q.get() -> ["A: How are you?"]
“Hey, process 1 saw the ‘How are you?’ but not the ‘Hi there!’, even though they both came from process 0.”
“Yep. It’s weird that process 1 saw the second write from process 0, but it didn’t see the first write. This violates the monotonic writes property. Note that if the two writes were from different processes, this would not violate the property. For example, this would be fine:
[id0] [id1] q.add("A: Hi there!") q.add("A: How are you?") q.get() -> ["A: How are you?"]
“From process 1’s perspective, it looks like the history of the chat log changed! Somehow, ‘A: Hello’ snuck in before ‘B: Hi’, even though process 1 had already seen ‘B: Hi’.”
“Yes, this violates a property called consistent prefix. Note that this is different from monotonic reads, which is not violated in this case. (Sadly, the Jepsen consistency page doesn’t have an entry for consistent prefix).
Reasoning about correctness in a distributed world
One way to think about what it means for a data structure implementation to be correct is to:
Define what it means for a particular execution history to be correct
Check that every possible execution history for the implementation satisfies this correctness criteria.
Step 2 requires doing a proof, because in general there are too many possible execution histories for us to check exhaustively. But, even if we don’t actually go ahead and do the formal proof, it’s still useful to think through step 1: what it means for a particular execution history to be correct.
As we move from sequential data structures to concurrent (multithreaded) ones and then distributed ones, things get a bit more complicated.
Recall that for the concurrent case, in order to check that a particular execution history was correct, we had to see if we could come up with a linearization. We had to try and identify specific points in time when operations took effect to come up with a sequential version of the history that met our sequential correctness criteria.
In Principles of Eventual Consistency, Sebastian Burckhardt proposed a similar type of approach for validating the execution history of a distributed data structure. (This is the approach that Viotti & Vukolic extended. Kyle Kingsbury references Viotti and Vukolic on the Jepsen consistency models page that I’ve linked to several times here).
Execution histories as a set of events
To understand Burckhardt’s approach, we first have to understand how he models a distributed data structure execution history. He models an execution history as a set of events, where each event has associated with it:
The operation (including arguments), e.g.:
get()
add(“Hi”)
A return value, e.g.
[“Hi”, “Hello”]
OK
He also defines two relations on these events, returns-before and same-session.
Returns-before
The returns-before (rb) relation models time. If there are two events, e1, e2, and (e1,e2) is in rb, that means that the operation associated with e1 returned before the operation associated with e2 started.
Let’s take this example, where the two add operations overlap in time:
Note that neither (e1,e2) nor (e2,e1) is in rb, because the two operations overlap in time. Neither one happens before the other.
Same-session
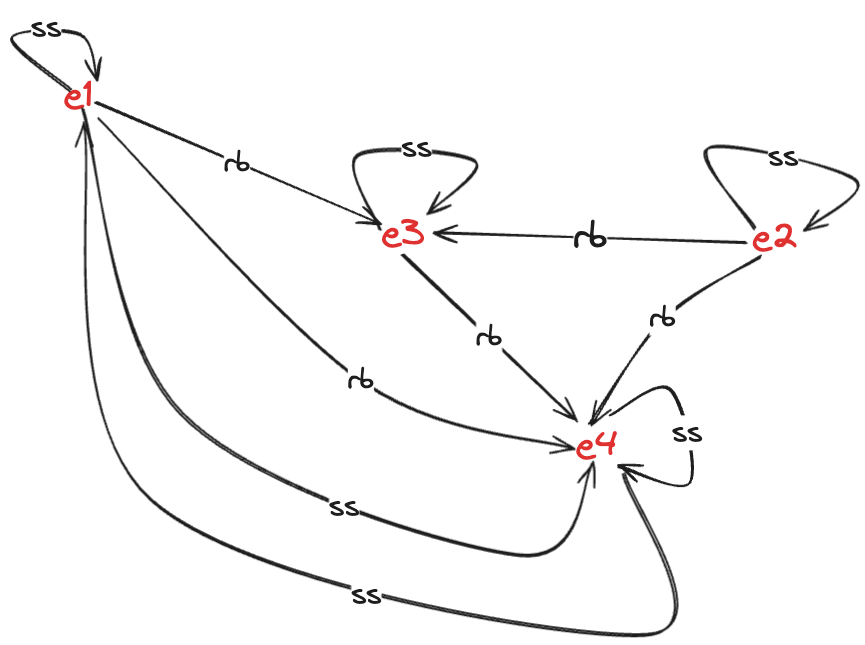
The same-session (ss) relation models the grouping of operations into processes. In the example above, there are three sessions (id0, id1, id2), and the same-session relation looks like this: ss={(e1,e1),(e1,e4),(e4,e1),(e4,e4),(e2,e2),(e3,e3)}. (Note: in this case, there are only two operations that are in the same session, e1 and e4
This is what the graph looks like with the returns-before (rb) and same-session (ss) relationship shown.
Explaining executions with visibility and arbitration
Here’s the idea behind Burckhardt’s approach. He defines consistency properties in terms of the returns-before (rb) relation, the same-session (ss) relation, and two other binary relations called visibility (vis) and arbitration (ar).
For example, an execution history satisfies read my writes if: (rb ∩ ss) ⊆ vis
In this scheme, an execution history is correct if we can come up with visibility and arbitration relations for the execution such that:
All of the consistency properties we care about are satisfied by our visibility and arbitration relations.
Our visibility and arbitration relations don’t violate any of our intuitions about causality.
You can think of coming up with visibility and arbitration relations for a history as coming up with an explanation for how the history makes sense. It’s a generalization of the process we used for linearizability where we picked a specific point in time where the operation took effect.
(1) tells us that we have to pick the right vis and ar (i.e., we have to pick a good explanation). (2) tells us that we don’t have complete freedom in picking vis and ar (i.e., our explanations have to make intuitive sense to human beings).
You can think of the visibility relation as capturing which write operations were visible to a read, and the arbitration relation as capturing how the data structure should reconcile conflicting writes.
Specifying behavior based on visibility and arbitration
Unfortunately, in a distributed world, we can no longer use the sequential specification for determining correct behavior. In the sequential world, writes are always totally ordered, but in the distributed world, we might have to deal with two different writes that aren’t ordered in a meaningful way.
What’s a valid value for ???. Let’s assume we’ve been told that: vis={(e1,e3),(e2,e3)}. This means that both writes are visible to process 3.
Based on our idea of how this data structure should work, e3 should either be: [“A”,”B”] or [“B”,”A”]. But the visibility relationship doesn’t provide enough information to tell us which one of these it was. We need some additional information to determine what the behavior should be.
This is where the arbitration relation comes in. This relation is always a total ordering. (For example, if ar specifies an ordering of e1->e2->e3, then the relation would be {(e1,e2),(e1,e3),(e2,e3)}. ).
If we define the behavior of our distributed queue such that the writes should happen in arbitration order, and we set ar=e1->e2->e3, then e3 would have to be get()->[“A”,”B”].
The above history is valid, because we can do: vis={(e1,e3),(e2,e4),(e3,e4))}, ar=e1->e2->e3->e4. Note that even though (e2,e3) is in ar, e2 is not visible to e3, and an operation only has to reflect the visible writes.
Note that we can come up with valid vis and ar relations for this history:
vis = {(e3,e2)}
ar = e1->e3->e2
But, despite the fact that we can come up with an explanation for this history, it doesn’t make sense to us, because e3 happened after e2. You can see why this is also referred to as session causality, because it violates our sense of causality: we read a write that happened in the future!
This is a great example of one of the differences between programming and formal modeling. It’s impossible to write a non-causal program (i.e., a program whose current output depends on future inputs). On the other hand, in formal modeling, we have no such restrictions, so we can always propose “impossible to actually happen in practice” behaviors to look at. So we often have to place additional constraints on the behaviors we generate with formal models to ensure that they’re actually realizable.
Sometimes we do encounter systems that record history in the wrong order, which makes the history look non-causal.
History is sometimes re-ordered in such a way that it looks like causality has been violated
Consistency as constraints on relations
The elegant thing about this relation-based model of execution histories is that the consistency models can be expressed in terms of them. Burckhardt conveniently defines two more relationships.
Session-order (so) is the ordering of events within each session, expressed as: so = rb ∩ ss
Happens-before (hb) is a causal ordering, in the sense of Lamport’s Time, Clocks, and the Ordering of Events in a Distributed System paper. (e1,e2) is in hb if (e1,e2) is in so (i.e., e1 comes before e2 in the same session), or if (e1,e2) is in vis (i.e., e1 is visible to e2), or if there’s some transitive relationship (e.g., there’s some e3 such that (e1,e3) and (e3,e2) are in so or vis.
Therefore, happens-before is the transitive closure of so ∪ vis, which we write as: hb = (so ∪ vis)⁺ . We can define no circular causality as no cycles in the hb relation or, as Burckhardt writes it: NoCircularCausality = acyclic(hb)
If you made it all of the way here, I’d encourage you to check out Burckhardt’s Principles of Eventual Consistency book. You can get the PDF for free by clicking the “Publication” button the web page.
All implementations of mutable state in a geographically distributed system are either slow (require coordination when updating data) or weird (provide weak consistency only).
When systems or organizations don’t work the way you think they should, it is generally not because the people in them are stupid or evil. It is because they are operating according to structures and incentives that aren’t obvious from the outside.
It is also counterproductive by encouraging researchers and consultants and organizations to treat errors as a thing associated with people as a component — the reification fallacy (a kind of over-simplification), treating a set of interacting dynamic processes as if they were a single process.
David Woods, Sidney Dekker, Richard Cook, Leila Johannensen, Nadine Sarter, Behind Human Error
We humans solve problems by engineering systems. In a sense, a system is the opposite of a classical atom. Where an atom was conceived of as an indivisible entity, a system is made up of a set of interacting components. These components are organized in such a way that the overall system accomplishes a useful set of functions as conceived of by the designers.
Unfortunately, it’s impossible to build a perfect complex system. It’s also the case that we humans are very bad at reasoning about the behavior of unfamiliar complex systems when they deviate from our expectations.
The notion of consistency in distributed systems are a great example of this. Because distributed systems are, well, systems, that can exhibit behaviors that wouldn’t happen with atomic systems. The most intuitive notion of consistency, called linearizability, basically means “this concurrent data structure behaves the way you would expect a sequential data structure works”. And linearizability doesn’t even encompass everything! It’s only meaningful if there is a notion of a global clock (which isn’t the case in a distributed system), and it also only covers the case of single objects, which means it doesn’t cover transactions across multiple objects However, ensuring linearizability is difficult enough that we typically need to relax our consistency requirements when we build distributed systems, which means we need to choose a weaker model.
What I love about consistency models is that they aren’t treated as correctness models. Instead, they’re weirdness models: different levels of consistency will violate our intuitions relative to linearizability, and we need to choose what level of weirdness that we can actually implement and that is good enough for our application.
These sorts of consistency problems, where systems exhibit behaviors that violate our intuitions, is not specific to distributed software systems. In some cases, the weirdness of the system behavior leads to a negative outcome, the sort of thing that we call an incident. Often the negative outcome is attributed to the behavior of an individual agent within the system, where it gets labeled as “human error”. But as Woods et al. point out in the quote above, this attribution is based on an incorrect assumption on how systems actually behave.
The problem isn’t the people within the system. The weirdness arises from the interactions.
Here are some proposed questions for interviewing someone for an SRE role. Really, these are just conversation starters to get them reflecting and discussing specific incident details.
The questions all start the same way: Tell me about a time when…
… action items that were completed in the wake of one incident changed system behavior in a way that ended up contributing to a future incident.
… someone deliberately violated the official change process in order to get work done, and things went poorly.
… someone deliberately violated the official change process in order to get work done, and things went well.
… you were burned by a coincidence (we were unlucky!).
… you were saved by a coincidence (we were lucky!).
… a miscommunication contributed to or exacerbated an incident.
… someone’s knowledge of the system was out of date, and them acting on this out-of-date knowledge contributed to or exacerbated an incident.
… something that was very obvious in hindsight was very confusing in the moment.
… somebody identified that something was wrong by noticing the absence of a signal.
… your system hit a type of limit that you had never breached before.
We know that not all of the services in our system are critical. For example, some of our internal services provide support functions (e.g., observability, analytics), where others provide user enhancements that aren’t strictly necessary for the system to function (e.g., personalization). Given that we have a limited budget to spend on availability (we only get four quarters in a year, and our headcount is very finite), we should spend that budget wisely, by improving the reliability of the critical services.
to crystalize this idea, let’s use the metaphor of a metal chain. Imagine a chain where each link in the chain represents one of the critical services in your system. When one of these critical services fails, the chain breaks, and the system goes down. To improve the availability of your overall system, we need to:
Identify what the critical services in your system are (find the links in the chain).
Focus your resources on hardening those critical services that need it most (strengthen the weakest links).
This is an appealing model, because it gives us a clear path forward on our reliability work. First, we figure out which of our services are the critical ones. You’re probably pretty confident that you’ve identified a subset of these services (including from previous incidents!), but you also know there’s the ever-present risk of a once-noncritical service drifting into criticality. Once you have defined this set, you can prioritize your reliability efforts on shoring up these services, focusing on the ones that are understood to need the most help.
Unfortunately, there’s a problem with this model: complex systems don’t fail the way that chains do. In a complex system, there are an enormous number of couplings between the different components. A service that you think of as non-critical can have surprising impact on a critical service in many different ways. As a simple example, a non-critical service might write bad data into the system that the critical service reads and acts on. The way that a complex systems fails is through unexpected patterns of interactionsamong the components.
The space of potential unexpected patterns of interactions is so large as to be effectively unbounded. It simply isn’t possible for a human being to imagine all of the ways that these interactions can lead to a critical service misbehaving. This means that “hardening the critical services” will have limited returns to reliability, because it still leaves you vulnerable to these unexpected interactions.
The chain model is particularly pernicious because the model act as a filter that shapes a person’s understanding of an incident. If you believe that every incident can be attributed to an insufficiently hardened critical service, you’ll be able to identify that pattern in every incident that happens. And, indeed, you can patch up the problem to prevent the previous incident from happening again. But this perspective won’t help you guard against a different kind of dangerous interaction, one that you never could have imagined.
If you really want to understand how complex systems fail, you need to think in terms of webs rather than chains. Complex systems are made up of webs of interactions, many of which we don’t see. Next time you’re doing a post-incident review, look for these previously hidden webs instead of trying to find the broken link in the chain.